About
Modern drug discovery and today's pharmacopeia is largely benefited from nature. More than 50% of approved drugs are natural products or natural product derivatives. It is estimated that there are about a million natural products have been isolated and many of them have been subjected to experimental assays to evaluate quantitative biological activities. By manually collecting and integrating these valuable data from individual literatures into a centralized database, the Natural Product Activity and Species Source Database (NPASS) has served as one of a leading data source for the NP research community since its first version release in 2017 (Nature Reviews Drug Discovery 22.11 (2023): 895–916).
NPASS has demonstrated a substantial influence on the field of natural product research since its initial release. The following examples illustrate this impact:
- Athina Gavriilidou et al. analyzed the biosynthetic diversity and NP discovery hotspots to guide NP research trends (Nature Microbiology, 7:726–735, 2022).
- Michael A. Skinnider et al. developed artificial intelligence algorithms for molecular AI design (Nature Machine Intelligence, 3:759–770, 2021).
- Laura Holzmeyer et al. revealed hidden relationships between phylogenetic, spatial, and bioactivity patterns of plant-derived NPs (PNAS, 117(22):12444–12451, 2020).
- PubChem 2025 update incorporated NPASS data to enhance coverage of bioactive natural compounds and their species origins (Nucleic Acids Research 53.D1 (2025): D1516–D1525).
Since 2018, a large number of new NPs have been found and biologically evaluated against a broad of biological targets by the research community, to better benefit the NP research community, we updated NPASS database to deposit more data points and more information layers of NP in the new version (v3.0). The NPASS database in the current version (V3.0) provides 204,023 unique natural products isolated from 48,940 source organisms and together with 1,048,756 activity records on 8,764 targets. Major changes in NPASS-v3.0 were summarized in the below table:
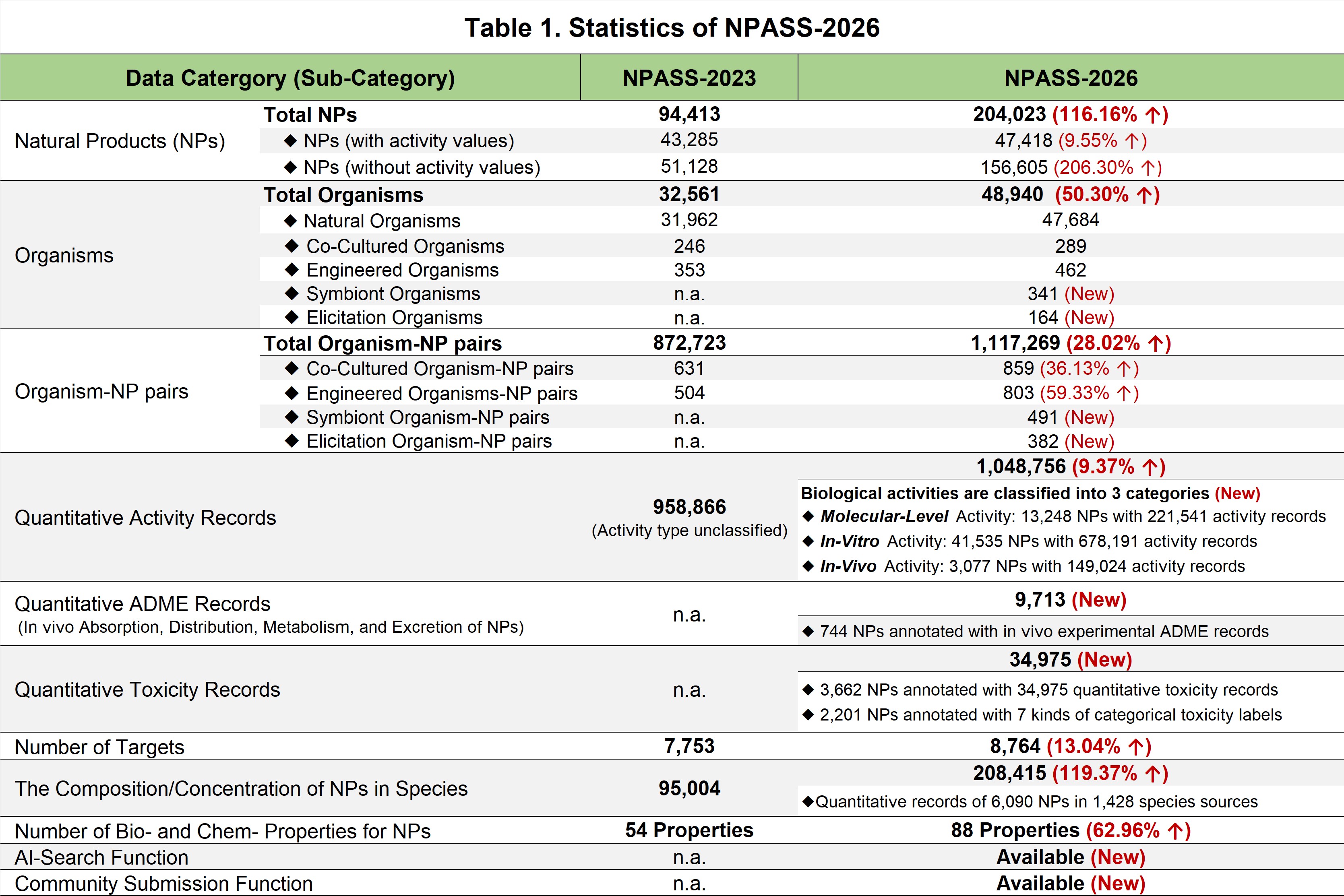
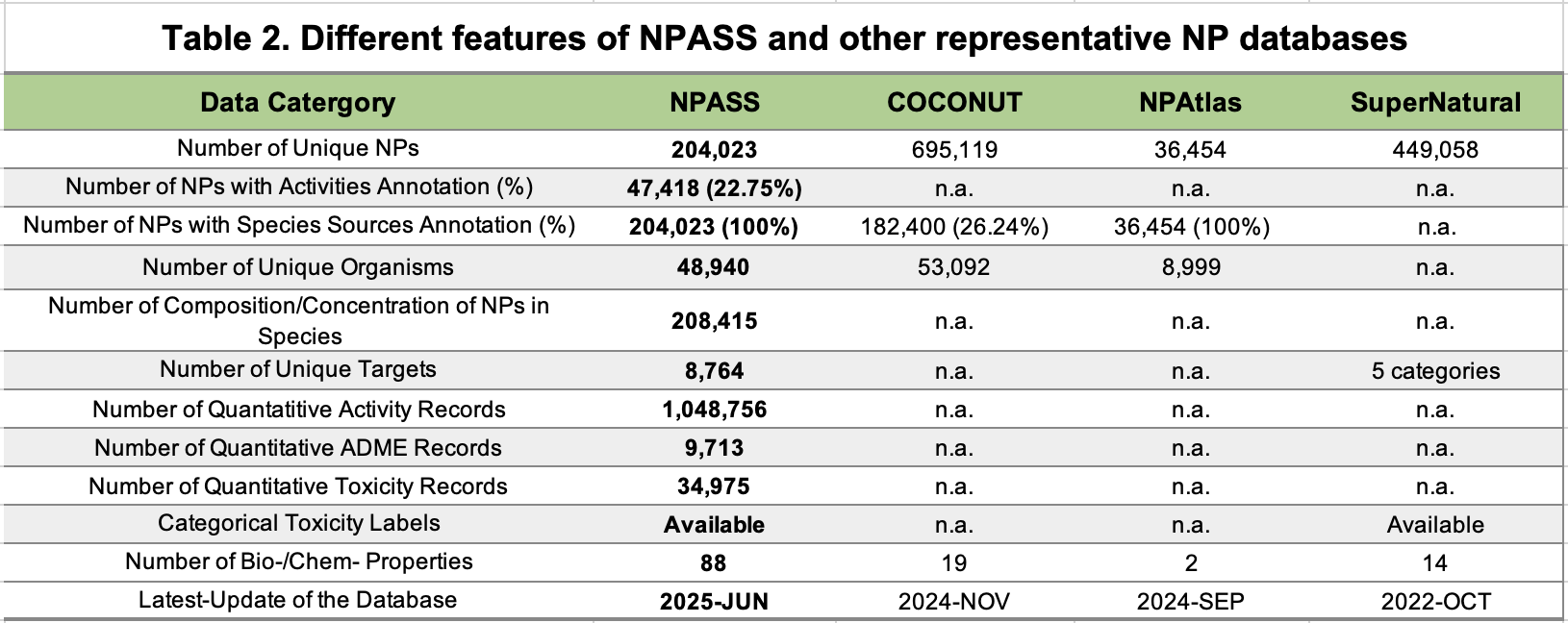
We also compare NPASS with several popular NP databases:
❖ Symbiosis as a rich source for natural product drug discovery
Symbiosis represents a powerful and underexplored resource in the search for novel natural products. Symbionts—microorganisms that live in close association with host organisms—significantly expand the chemical space available for therapeutic development. These relationships, which can be commensal, mutualistic, or parasitic, are often mediated and regulated by specialized natural products that facilitate communication, defense, and metabolic cooperation within the symbiotic system.
The coevolution of microbial symbionts with their hosts has led to the emergence of highly specialized biosynthetic capabilities, resulting in the production of structurally unique and biologically potent secondary metabolites. Many of these compounds exhibit striking bioactivities, including antimicrobial, anticancer, and immunosuppressive properties, making them highly valuable for drug discovery and commercial development.
In recent years, numerous novel bioactive compounds have been identified through the study of symbiotic systems, underscoring their immense potential as a source of previously untapped chemical diversity. (Nature Communications 14.1 (2023): 7650.) (Nature chemistry 14.6 (2022): 701-712.)This curated collection enables users to browse known host-microbe relationships and their associated compounds, serving as a valuable resource for natural product research.
❖ Elicitation: An invaluable strategy for unlocking natural product drug discovery
Elicitation has emerged as a pivotal strategy in natural product drug discovery, particularly for harnessing the rich biosynthetic potential of Actinobacteria. Although genome sequencing has revealed an abundance of biosynthetic gene clusters (BGCs) capable of producing diverse bioactive compounds, many remain silent or cryptic under standard laboratory conditions. This silence often stems from the absence of the complex ecological cues—such as nutrient limitation, microbial competition, or host-derived signals—that naturally trigger their expression in the environment. As traditional high-throughput screening methods have seen diminishing returns, elicitation offers a powerful means to revive interest in natural product discovery by reactivating these dormant pathways.(Nature Reviews Microbiology 18.10 (2020): 546-558.)
By mimicking natural environmental stimuli, elicitors—such as small signaling molecules, stress hormones—can effectively induce the expression of otherwise inaccessible BGCs. This approach not only expands the accessible chemical space for drug discovery but also increases the likelihood of identifying novel antibiotics and other therapeutic agents.To cater to this need, we manually collected elicitation-related metabolites from published literature, compiling compounds that have been experimentally shown to activate silent or poorly expressed biosynthetic gene clusters. This curated dataset serves as a valuable resource for understanding the chemical signals involved in natural product biosynthesis and supports the rational design of elicitation strategies in NP drug discovery.
❖ Co-culture microorganisms and engineered microorganisms for optimized production of high-value NPs
Recently years, deeper understanding in biosynthesis mechanisms, advances in synthetic biology and metabolic/genetic reprogramming strategies are evolving the NP research paradigm. In the nature, microorganisms merely grow and function (e.g., producing secondary metabolites) independently, but cooperate with other species in their surrounding living system. In addition, many synthetic gene clusters for biosynthesis of high-value NPs were usually silenced in natural organisms.
By manipulating the cultivation system or engineering metabolic pathways/synthetic gene clusters, NPs can be produced by organisms in more efficient and programmable manners. Co-culture and engineering natural species are two important synthetic biology strategies to achieve such purposes. By activating silenced synthetic pathways or introducing synthetic enzymes to model species, or by recovering microbe-microbe interactions, organism engineering and co-culture systems (also termed microbial consortia) are emerging strategies to produce novel NPs or increase yield of high-value NPs.
A comprehensive dataset of co-culture and engineered organisms is of importance for the NP research community, such as to deeper understand the potentials and diversity of biosynthesis space of organisms for NPs and drug discovery. To cater this need, we extensively searched PubMed and manually curated co-culture combinations and engineered organisms from literature.
❖ The workflow of developing NPASS is illustrated in the below figure

 DATA SOURCES
DATA SOURCES
I. Species source of natural products
Species source information is mainly from manually inspection of publications. Besides, we surveyed existing natural product-related databases to find species source annotations.
♦ Manually annotated from publications
Multiple keywords/keywords conbinations are used to search literatures that may revelant to isolation, total synthesis, activity evaluation of NPs through PubMed. These keywords include natural product, NP, nature, marine, plant, microbe, microbial, bacterium, bacteria, bacterial, fungus, fungi, fungal, species, traditional medicine, medicinal, indigenous, folk, herb, herbal, herbalism, Chinese medicine, TCM, Ayurveda, activity, active, bioactive, potent, potency, IC50, Ki, EC50, GI50, and MIC. Searched publications are subjected to first-step manually check the title to confirm if the literature is really revelant. Then, full articles of these relavent publications are downloaded for manually checking the species source (including if the NP is novel structure claimed by authors, species collection location and time, species part used for isolation, etc.) of corresponding natural products.
♦ Collected from existing databases
Few existing databases include a part of species source information of natural products. These databases includes: TCM-ID, TCMID, TCM@TaiWan,COCONUT, TCMSP, UNPD, TM-MC, StreptomeDB, TTD, TarNet, ChEBI, and HerDing. Therefore, NP names/structures are searched against these databases to extract species source information.
II. Biological activities of natural products
Quantitative activity data of NPs against specific targets (including: target information, activity type and values, compound dose etc.) are integrated from ChEMBL database (ver-35) and manually curated from literatures searched described in previous paragraph. Collected activity types includes inhibition concentration/dose like IC50/IC90/ID50, activity concentrations like AC/AC40/AC50/Potency, microbial inhibitory or lethal concentrations like MIC/MFC/MBC/FC, growth inhibitory concentrations like GI/GI50/TGI, percentage inhibition at fixed concentrations like inhibition rate, efective contrations/doses like EC50/EC90/ED50/ED90, equilibrium inhibition constant Ki, lethal concentrations/doses like LC/LC50/LC90/LD50/LD90, inhibition zone IZ, equilibrium binding constant Kd, ratio IC50/ratio EC50/ratio/Ki, cytotoxic concentrations like CC25/CC50/CC90/CC100, and toxic concentration/dose like TC50/TD50. More than half of activity values are stored as the unit of nM, other units include ug/ml, mg/kg, %, mm, and so on.
In NPASS 3.0, biological activities are further categorized into in vitro, in vivo, molecular-level (e.g., targeting single proteins or protein families), ADME (absorption, distribution, metabolism, and excretion), and quantitative toxicities (e.g., LD50, LC50, survival rates), enabling more precise functional annotations.
NATURAL PRODUCT PROFILE
I. Natural products
♦ Natural products chemical representation
Common name, synonyms, IUPAC Name, Standard InCHI, Standard InCHI Key, Canonical SMILES, and MOL file.
♦ Natural products physical & chemical & ADMET properties
The Natural products physical & chemical & ADMET properties are calculated using ADMETLab3.0. Properties include Molecular formula, molecular weight, AlogP, # hydrogen bond donor, # hydrogen bond acceptor, polar surface area, # rotatable bond, # aromatic rings, # heavy atoms, etc.
II. Clinical/approved drugs
Clinical trial and approved drugs are collected from TTD (Therapeutical Target Database), Drug Bank, and ChEMBL database.
III. Similarity between molecules
Structure similarity between molecules is defined by Tanimoto coefficient (Tc). Tc is calculated by using ECFP fingerprints according to below equation:

Where 'X' and 'X' are fingerprints of two molecules, and 'xi' and 'yi' are the ith bits in each fingerprint. "∧" and "∨" represent the bitwise "and" and bitwise "or", respectively. Ts(xi,yi) is the value of Tanimoto coefficient which is equal to the total number of common substructure features divided by the total number of unique substructures existing in both molecules.
Tc lies between [0,1] where '1' represents the highest similarity between molecule 'X' and 'Y'.
Tc scores between NPs are pre-calculated and stored in NPASS database. While Tc score between user-query-molecule and NPs is calculated realtime by using functions of chemfp toolkit.
To better understand the biological properties of NPs, we integrated bioactivity descriptors from the Chemical Checker into NPASS. These descriptors span five biological levels—chemistry, targets, networks, cells, and clinics. Using UMAP for dimensionality reduction and ChemPlot for visualization, we mapped each NP in five 2D similarity spaces. Bioactivity similarities were quantified using Euclidean distances, enabling exploration of top-N similar NPs within each sub-space. This approach helps infer potential activities of NPs lacking experimental data by comparing them to biologically similar compounds.
SOURCE ORGANISM PROFILE
I. Organism taxonomy information
All organism names extracted from orginal files are firstly matched to scientific names from NCBI taxonomy database, then unmatched names are matched to synonyms from NCBI Taxonomy Database and transformed to scientific name when matched. Finally, those organism names that can not match to any scientific names or synonyms are kept in orginal format. After matching to NCBI TaxonomyDB, taxonomy IDs are recorded to generate external links of organisms.
II. Organism external links
About 60% and 93% source species can be matched to NCBI Taxonomy database at species level and genus level, respectively. For these species, Taxonomy IDs are annotated so that users can review taxonomic details from NCBI Taxonomy database. For the remaining about 7% species which can not match to any entries in NCBI Taxonomy database, we will further check the accuracy of species name and annotate taxonomic information from original literatures. Apart from NCBI Taxonomy database, species organisms are also links to other databases such as World Register of Marine Species (WoRMS) when data available.
TARGET PROFILE
Targets are classified into several categories according to classification of ChEMBL database, including 'Individual protein', 'Protein family', 'Protein complex', 'Protein-protein interaction', 'Cell line', 'Organism', and so on. Targets are corsslinked to TTD, Uniprot, ChEMBL, IUPHAR/BPS when possible.