Natural Product: NPC93984
Natural Product: NPC93984
| Natural Product ID | NPC93984 |
|
Common Name
The InCHIKey will be temporarily assigned as the "Common Name" if no IUPAC name or alternative short name is available.
| DSNIKOZTDZBWKD-XMNJDQQWSA-N |
| IUPAC Name | n.a. |
| Synonyms | |
| Synthetic Gene Cluster | n.a. |
| ChEMBL Identifier | n.a. |
| PubChem CID |
3085251 |
| Chemical Classification |
|
The Chemical Classification was calculated by Classyfire, a software for chemical taxonomy calculation. Reference: DOI:10.1186/s13321-016-0174-y.
 Chemical Representations
Chemical Representations
| Standard InCHIKey | DSNIKOZTDZBWKD-XMNJDQQWSA-N |
| Standard InCHI | InChI=1S/C32H40O8/c1-15-7-8-19-22(15)24-20(13-21(30(19,6)37)38-17(3)33)32(27(35)40-24)14-31-12-11-28(32,4)25(31)23-18(9-10-29(31,5)36)16(2)26(34)39-23/h7,11-12,18-25,36-37H,2,8-10,13-14H2,1,3-6H3/t18?,19?,20?,21-,22?,23+,24+,25?,28?,29-,30+,31?,32?/m1/s1 |
| SMILES | CC1=CCC2C1[C@@H]1C(C[C@H]([C@@]2(C)O)OC(=O)C)C2(CC34C=CC2(C)C3[C@@H]2C(CC[C@@]4(C)O)C(=C)C(=O)O2)C(=O)O1 |
 Calculated Properties
Calculated Properties
Physi-Chem Properties
MedChem Properties
ADMET Properties (ADMETlab3.0)
ADMET: Absorption
ADMET: Distribution
ADMET: Metabolism
ADMET: Excretion
ADMET: Toxicity
 Species Source
Species Source
| Organism ID | Organism Name | Taxonomy Level | Family | SuperKingdom | Isolation Part | Collection Location | Collection Time | Reference |
|---|---|---|---|---|---|---|---|---|
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | Flowers | n.a. | n.a. | DOI[10.5897/JMPR.9000078] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | n.a. | flower | n.a. |
PMID[12130858] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | n.a. | n.a. | n.a. |
PMID[26099993] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | Flowers | n.a. | n.a. |
PMID[28156114] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | n.a. | n.a. | n.a. |
PMID[29400471] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | Aerial Parts | n.a. | n.a. |
PMID[30726671] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | n.a. | n.a. | n.a. | Database[COCONUT] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | n.a. | n.a. | n.a. | Database[HerDing] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | n.a. | n.a. | n.a. | Database[TCMID] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | n.a. | n.a. | n.a. | Database[TCM_Taiwan] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | n.a. | n.a. | n.a. | Database[TM-MC] |
| NPO22258 | Chrysanthemum indicum | Species | Asteraceae | Eukaryota | n.a. | n.a. | n.a. | Database[UNPD] |
Note for Reference:
In addition to directly collecting NP source organism data from primary literature (where reference will provided as NCBI PMID or DOI links), NPASS also integrated them from below databases:
☉ UNPD: Universal Natural Products Database [PMID: 23638153].
☉ StreptomeDB: a database of streptomycetes natural products [PMID: 33051671].
☉ TM-MC: a database of medicinal materials and chemical compounds in Northeast Asian traditional medicine [PMID: 26156871].
☉ TCM@Taiwan: a Traditional Chinese Medicine database [PMID: 21253603].
☉ TCMID: a Traditional Chinese Medicine database [PMID: 29106634].
☉ TCMSP: The traditional Chinese medicine systems pharmacology database and analysis platform [PMID: 24735618].
☉ HerDing: a herb recommendation system to treat diseases using genes and chemicals [PMID: 26980517].
☉ MetaboLights: a metabolomics database [PMID: 27010336].
☉ FooDB: a database of constituents, chemistry and biology of food species [www.foodb.ca].
 NP Quantity Composition/Concentration
NP Quantity Composition/Concentration
| Organism ID | Organism Name | Organism Material Preparation | Organism Part | NP Quantity (Standard) | NP Quantity (Minimum) | NP Quantity (Maximum) | Quantity Unit | Reference |
|---|
Note for Reference:
In addition to directly collecting NP quantitative data from primary literature (where reference will provided as NCBI PMID or DOI links), NPASS also integrated NP quantitative records for specific NP domains (e.g., NPS from foods or herbs) from domain-specific databases. These databases include:
☉ DUKE: Dr. Duke's Phytochemical and Ethnobotanical Databases.
☉ PHENOL EXPLORER: is the first comprehensive database on polyphenol content in foods [PMID: 24103452], its homepage can be accessed at here.
☉ FooDB: a database of constituents, chemistry and biology of food species [www.foodb.ca].
 Biological Activity
Biological Activity
Molecular-level activity
| Target ID | Target Type | Target Name | Target Organism | Activity Type | Activity Relation | Value | Unit | Reference |
|---|
In vitro activity
| Target ID | Target Type | Target Name | Target Organism | Activity Type | Activity Relation | Value | Unit | Reference |
|---|
In vivo activity
| Target ID | Target Type | Target Name | Target Organism | Activity Type | Activity Relation | Value | Unit | Reference |
|---|
 Experimental ADME
Experimental ADME
| Experiment Model | Experiment Tissue | ADME Type | ADME Relation | ADME Value | ADME Unit | Reference |
|---|
 Experimental Toxicity
Experimental Toxicity
Quantitative toxicity
| Experiment Model | Experiment Organism | Toxicity Type | Toxicity Relation | Toxicity Value | Toxicity Unit | Reference |
|---|
Common Abbreviations:
LC: Lethal Concentration; LD: Lethal Dose; LT:Lethal Time; NOAEL: No-observed-adverse-effect Level; BMDL: Benchmark Dose Lower Confidence Limit; BMD: Benchmark Dose; BMC:Benchmark Concentration; LOAEL: Lowest Observed Adverse Effect Level; RfD:Reference Dose; RfC:Reference Concentration; MRL: Minimal Risk Level; MEG: Maximum Exposure Guideline; PAC: Protective Action Criteria
Categorical toxicity labels
| Hepatotoxicity | Carcinogenicity | Mutagenicity | Cardiotoxicity | Respiratory Toxicity | Eye Irritation | Endocrine Disruption |
|---|---|---|---|---|---|---|

|

|

|

|

|

|

|
Note for Reference:
In addition to directly collecting NP quantitative data from primary literature (where reference will provided as NCBI PMID or DOI links), NPASS also integrated NP toxicity records from domain-specific databases. These databases include:
☉ ToxValDB: a curated database that compiles quantitative toxicity values for chemicals from diverse public sources to support toxicological research and risk assessment.
☉ TOXRIC: a comprehensive, free-to-access, online database providing toxicological/feature data. The toxicity labels are retrieved from this database. [PMID: 36400569]
 Chemically structural similarity
Chemically structural similarity
Similar Active Natural Products in NPASS
Top-200 similar NPs were calculated against the active-NP-set (includes approximately 50,000 NPs with experimentally-derived bioactivity available in NPASS)
Similarity is measured using the Tanimoto coefficient (Tc) , which compares the binary fingerprints of two molecules. Tc is calculated as the intersection divided by the union of '1' bits in the fingerprints, ranging from 0 to 1, with 1 indicating highest similarity.
● The left chart: Distribution of similarity level between NPC93984 and all remaining natural products in the NPASS database.
● The right table: Most similar natural products (Tc>=0.5 or Top200).
| Similarity Score | Similarity Level | Natural Product ID |
|---|---|---|
| 0.7179 | Intermediate Similarity | NPC471884 |
| 0.7143 | Intermediate Similarity | NPC488057 |
| 0.679 | Remote Similarity | NPC488062 |
| 0.6145 | Remote Similarity | NPC488068 |
| 0.5882 | Remote Similarity | NPC481225 |
| 0.5882 | Remote Similarity | NPC481224 |
| 0.5632 | Remote Similarity | NPC96585 |
| 0.5632 | Remote Similarity | NPC601364 |
| 0.5517 | Remote Similarity | NPC599963 |
| 0.5402 | Remote Similarity | NPC488061 |
| 0.5281 | Remote Similarity | NPC488059 |
| 0.5222 | Remote Similarity | NPC488060 |
| 0.5185 | Remote Similarity | NPC609930 |
Similar Clinical/Approved Drugs
Similarity level is defined by Tanimoto coefficient (Tc) between two molecules.
● The left chart: Distribution of similarity level between NPC93984 and all drugs/candidates.
● The right table: Most similar clinical/approved drugs (Tc>=0.5 or Top200).
| Similarity Score | Similarity Level | Drug ID | Developmental Stage |
|---|---|---|---|
| NPD |
Bioactivity similarity
 Bioactivity similarity
Bioactivity similarity
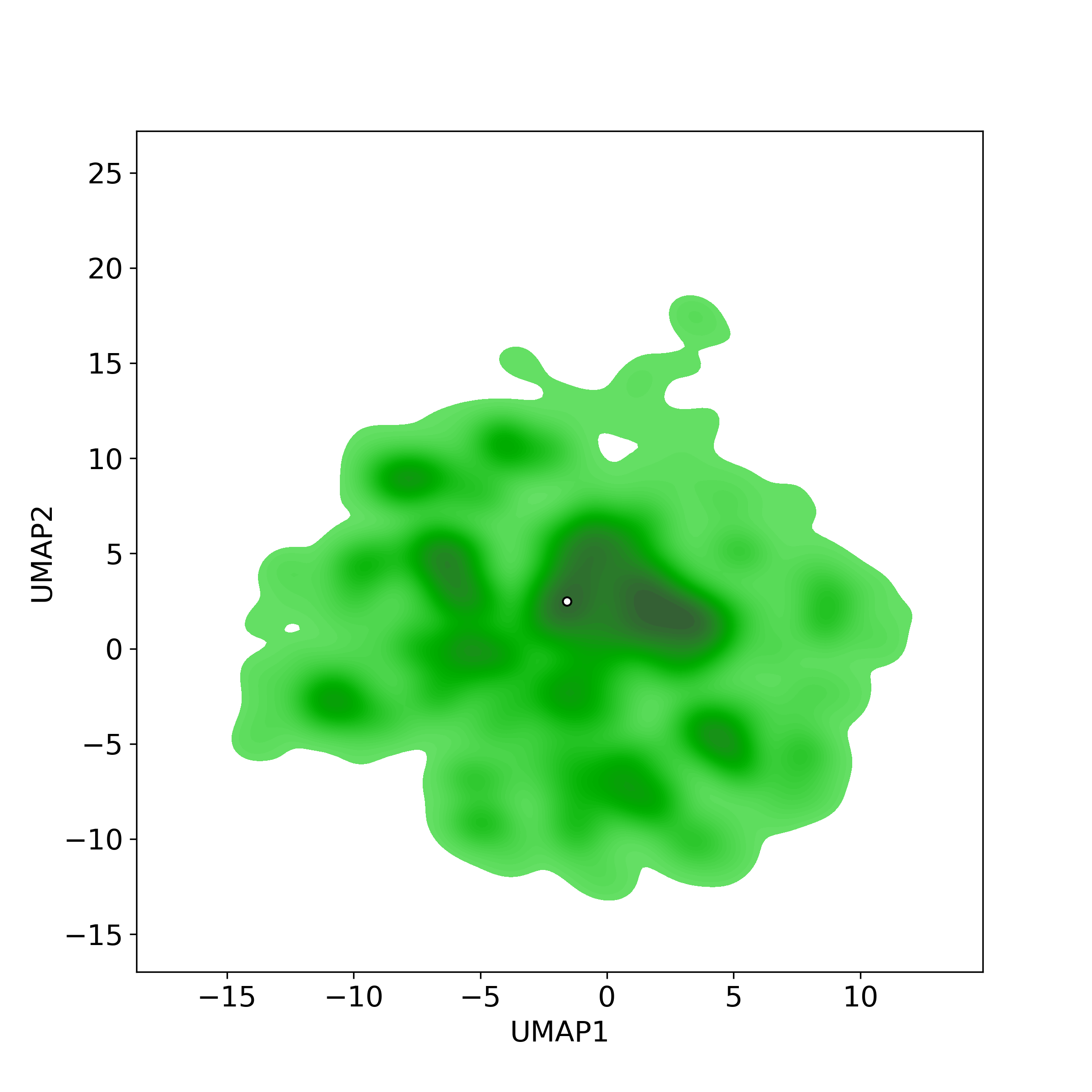
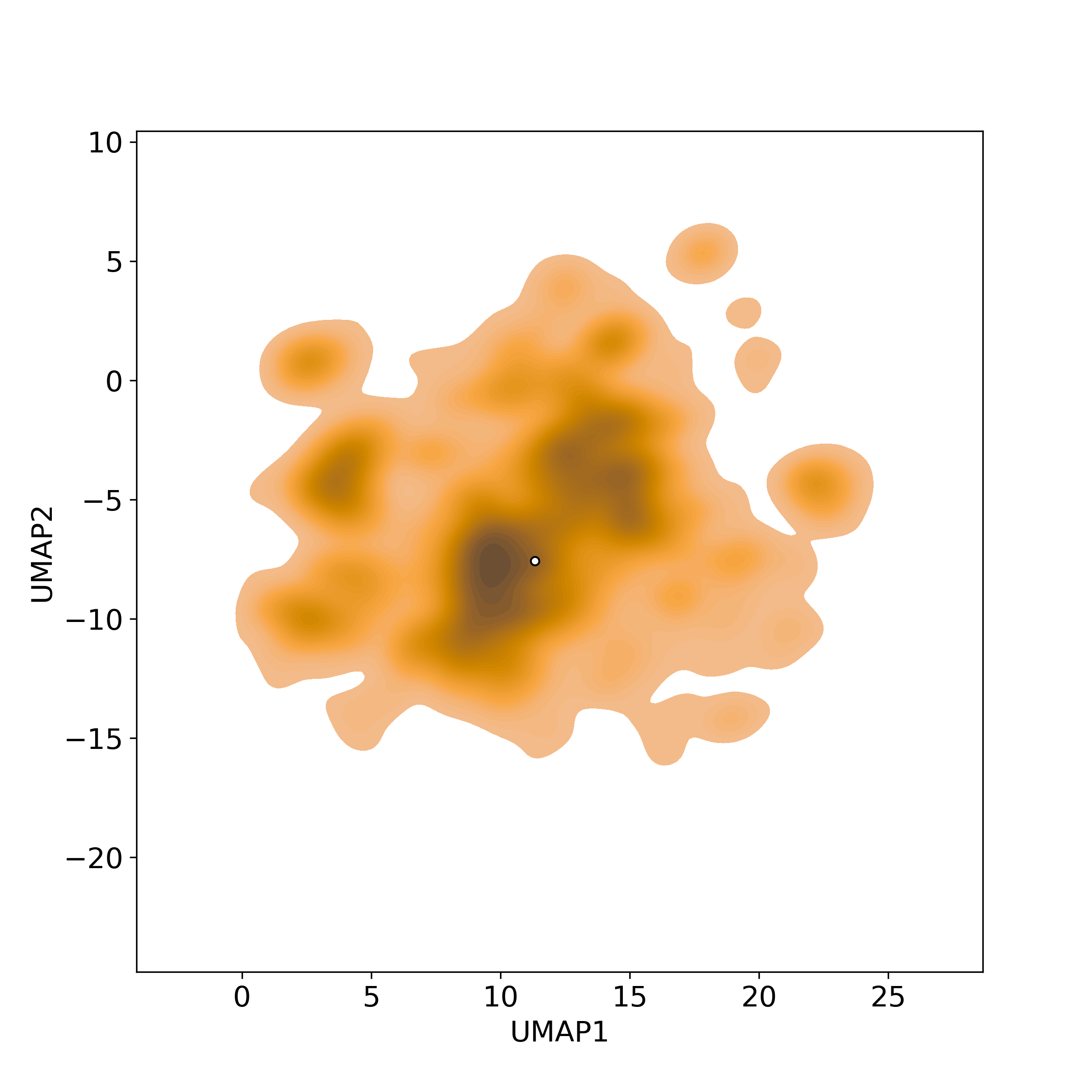
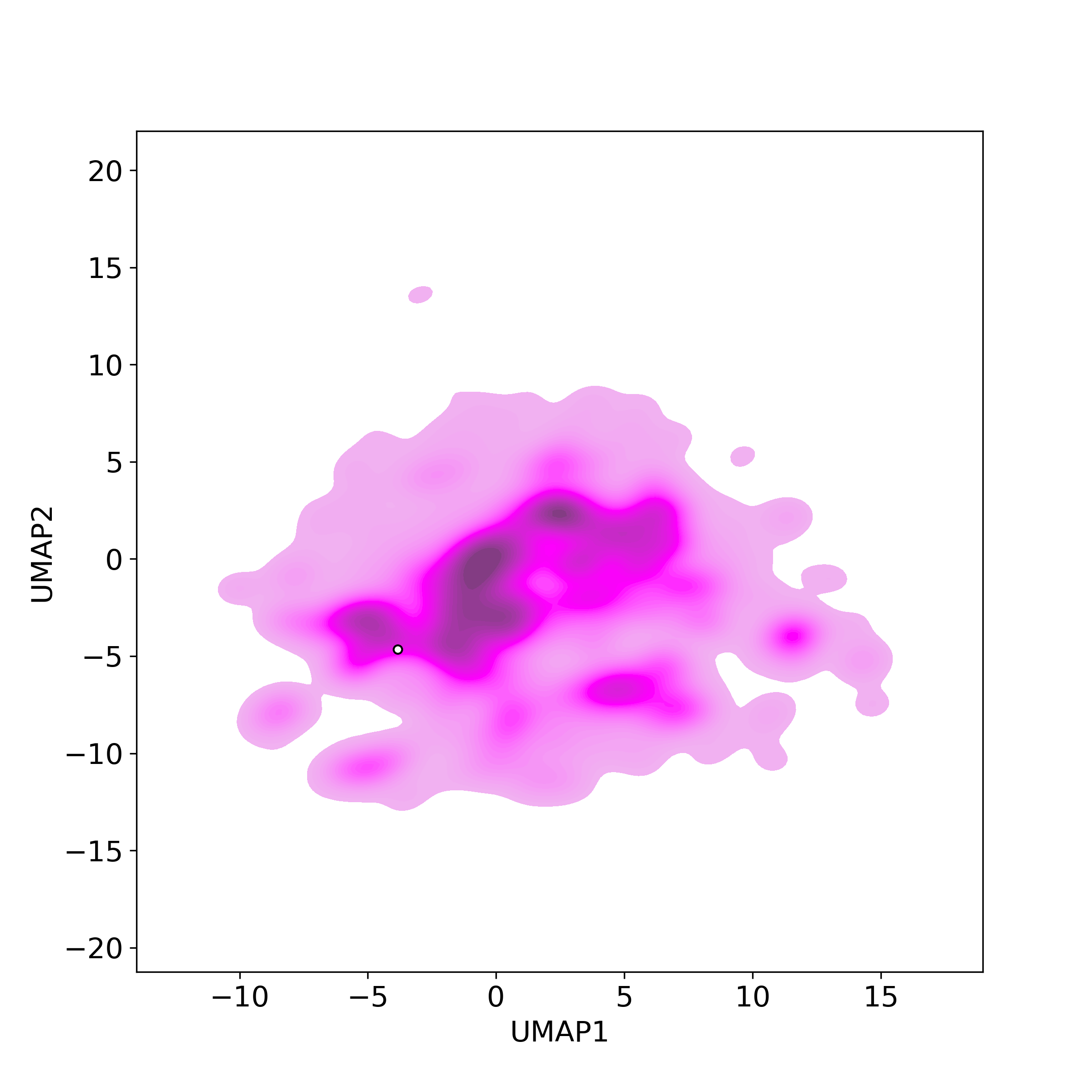
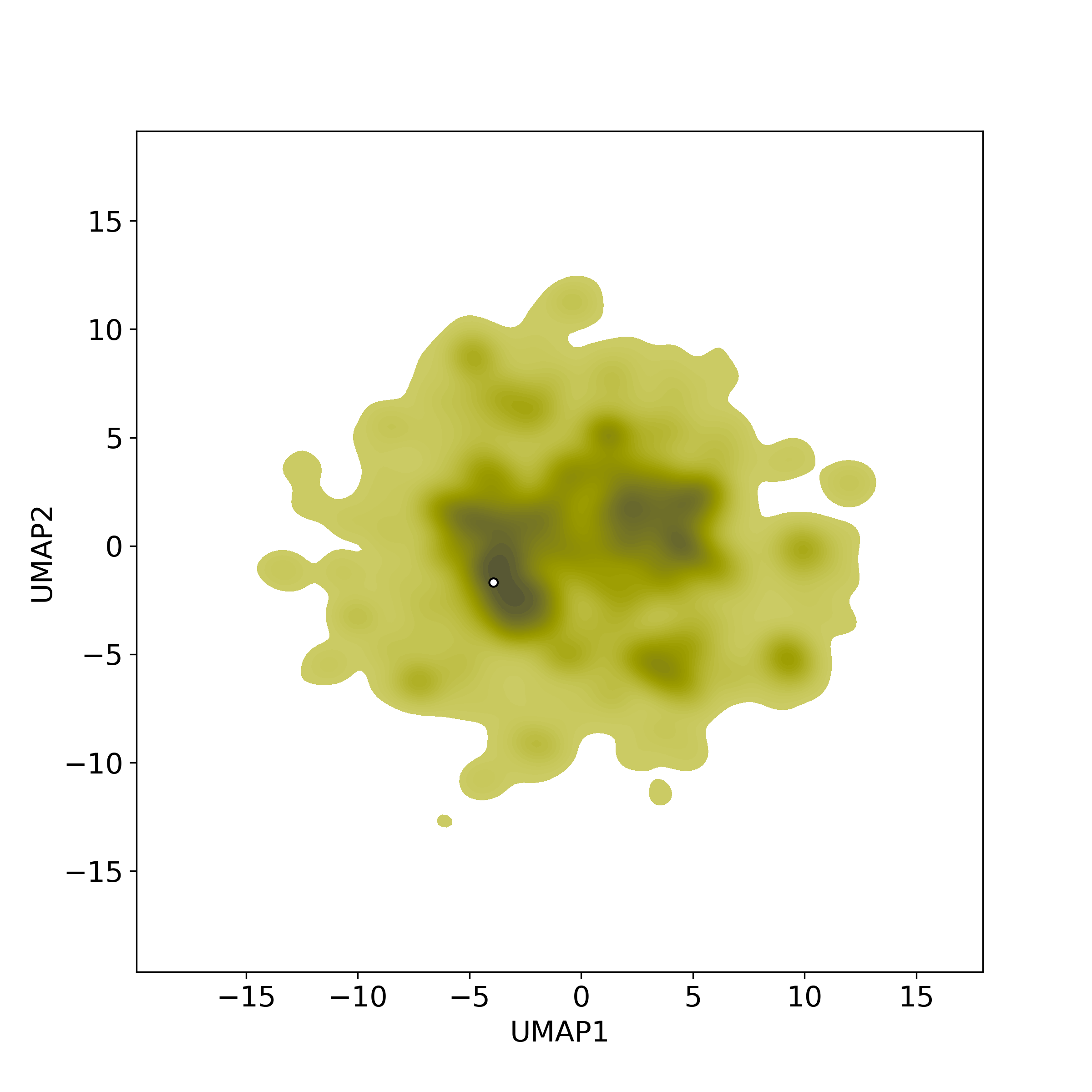
Similar Natural Products in NPASS
Similarity level is defined by Bioactivity similarity was calculated based on bioactivity descriptors of compounds. The bioactivity descriptors were calculated by a recently developed AI algorithm Chemical Checker (CC) [Nature Biotechnology, 38:1087–1096, 2020; Nature Communications, 12:3932, 2021], which evaluated bioactivity similarities at five levels:
☉ A: chemistry similarity;
☉ B: biological targets similarity;
☉ C: networks similarity;
☉ D: cell-based bioactivity similarity;
☉ E: similarity based on clinical data.
Those 5 categories of CC bioactivity descriptors were calculated and then subjected to manifold projection using UMAP algorithm, to project all NPs on a 2-Dimensional space. The current NP was highlighted with a small circle in the 2-D map. Below figures: left-to-right, A-to-E.