Natural Product: NPC89521
Natural Product: NPC89521
| Natural Product ID | NPC89521 |
|
Common Name
The InCHIKey will be temporarily assigned as the "Common Name" if no IUPAC name or alternative short name is available.
| KDGYLZNIUHEJCM-VFNNOXKTSA-N |
| IUPAC Name | n.a. |
| Synonyms | |
| Synthetic Gene Cluster | n.a. |
| ChEMBL Identifier | n.a. |
| PubChem CID |
11384492 |
| Chemical Classification |
|
The Chemical Classification was calculated by Classyfire, a software for chemical taxonomy calculation. Reference: DOI:10.1186/s13321-016-0174-y.
 Chemical Representations
Chemical Representations
| Standard InCHIKey | KDGYLZNIUHEJCM-VFNNOXKTSA-N |
| Standard InCHI | InChI=1S/C23H28O7/c1-8-9-15-10-17(25-3)23(18(11-15)26-4)30-14(2)21(24)16-12-19(27-5)22(29-7)20(13-16)28-6/h8-14H,1-7H3/b9-8+/t14-/m0/s1 |
| SMILES | C/C=C/c1cc(c(c(c1)OC)O[C@@H](C)C(=O)c1cc(c(c(c1)OC)OC)OC)OC |
 Calculated Properties
Calculated Properties
Physi-Chem Properties
| Molecular Weight: | 416.18 | Volume: | 429.691 Van der Waals volume.
|
| Dense: | 0.969 | LogP: | 2.919 The logarithm of the n-octanol/water distribution coefficients.
|
| logD7.4: | 3.23 The logarithm of the n-octanol/water distribution coefficient at pH=7.4.
|
LogS: | -4.132 The logarithm of aqueous solubility value.
|
| Rotatable Bonds: | 10.0 | Rigid Bonds: | 14.0 |
| TPSA: | 72.45 Topological Polar Surface Area.
|
H-Bond Acceptor: | 7.0 |
| H-Bond Donor: | 0.0 | Rings: | 2.0 |
| Heavy Atoms: | 7.0 |
MedChem Properties
| QED Drug-Likeness Score: | 0.531 | GASA: | 0.0 GASA represents the probability of being difficult to synthesize, ranging from 0 to 1.
|
| Synthetic Accessibility Score: | 2.821 | Fsp3: | 0.348 |
| MCE-18: | 32.0 MCE-18 stands for medicinal chemistry evolution.MCE-18≥45 is considered a suitable value.
|
Lipinski Rule-of-5: | Rejected |
| Pfizer Rule: | Rejected | GSK Rule: | Accepted |
| Golden Triangle Rule: | Rejected | BMS Rule: | 0 |
| Chelating Alert: | 0 | PAINS Alert: | 0 |
| Colloidal aggregators: | 0.051 | Fluc inhibitor: | 0.764 The fluc inhibitor value is the probability of being fLuc inhibitors, within the range of 0 to 1.
|
| Blue fluorescence: | 0.365 The blue fluorescence value is the probability of being blue fluorescence, within the range of 0 to 1
|
Green fluorescence: | 0.517 The green fluorescence value is the probability of being green fluorescence, within the range of 0 to 1
|
| Reactive compounds: | 0.512 | Promiscuous compounds: | 0.057 |
ADMET Properties (ADMETlab3.0)
ADMET: Absorption
| Caco-2 Permeability: | -4.848 | MDCK Permeability: | -4.694 |
| Pgp-inhibitor: | 0.818 | Pgp-substrate: | 0.189 |
| PAMPA: |
0.003 The experimental data for Peff was logarithmically transformed (logPeff). Molecules with log Peff values below 2.0 were classified as low-permeability (Category 0), while those with log Peff values exceeding 2.5 were classified as high-permeability (Category 1).
|
Human Intestinal Absorption (HIA): | 0.0 |
| 20% Bioavailability (F20%): | 0.025 | 30% Bioavailability (F30%): | 0.008 |
| 50% Bioavailability (F50%): | 0.612 |
ADMET: Distribution
| Blood-Brain-Barrier Penetration (BBB): | 0.458 | MRP1: | 0.998 |
| Plasma Protein Binding (PPB): | 95.354% | Volume Distribution (VD): | -0.022 |
| Fu: |
3.465% The fraction unbound in plasms.
|
OATP1B1 inhibitor: | 0.989 |
| OATP1B3 inhibitor: | 0.975 | BCRP inhibitor: | 0.474 |
| BSEP inhibitor: | 1.0 |
ADMET: Metabolism
| CYP1A2-inhibitor: | 0.422 | CYP1A2-substrate: | 0.987 |
| CYP2C19-inhibitor: | 0.998 | CYP2C19-substrate: | 0.982 |
| CYP2C9-inhibitor: | 0.031 | CYP2C9-substrate: | 0.0 |
| CYP2D6-inhibitor: | 0.065 | CYP2D6-substrate: | 0.965 |
| CYP3A4-inhibitor: | 1.0 | CYP3A4-substrate: | 0.998 |
| CYP2B6-substrate: | 0.005 | CYP2C8-inhibitor: | 1.0 |
| HLM stability: |
0.941 Human liver microsomal (HLM) stability. Category 0: stable+ (HLM > 30 min); Category 1: unstable- (HLM ≤ 30 min). The output value is the probability of human liver microsomal instability, where a value closer to 1 indicates a higher likelihood of instability.
|
ADMET: Excretion
| Clearance (CL): | 6.347 | Half-life (T1/2): | 0.887 |
ADMET: Toxicity
| hERG Blockers: | 0.256 | hERG Blockers (10um): | 0.59 |
| Human Hepatotoxicity (H-HT): | 0.666 | Drug-induced Liver Injury (DILI): | 0.664 |
| AMES Toxicity: | 0.307 | Rat Oral Acute Toxicity: | 0.344 |
| Maximum Recommended Daily Dose: | 0.639 | Skin Sensitization: | 0.767 |
| Carcinogencity: | 0.632 | Eye Corrosion: | 0.014 |
| Eye Irritation: | 0.42 | Respiratory Toxicity: | 0.527 |
| Drug-induced Neurotoxicity: | 0.794 | Ototoxicity: | 0.429 |
| Hematotoxicity: | 0.517 | Drug-induced Nephrotoxicity: | 0.623 |
| Genotoxicity: | 0.24 | RPMI-8226 Immunitoxicity: | 0.266 |
| A549 Cytotoxicity: | 0.268 | Hek293 Cytotoxicity: | 0.51 |
| BCF: |
1.958 Bioconcentration factors are used for considering secondary poisoning potential and assessing risks to human health via the food chain. The unit is -log10[(mg/L)/(1000*MW)].
|
IGC50: |
3.882 48 hour Tetrahymena pyriformis IGC50. The unit of IGC50 is -log10[(mg/L)/(1000*MW)].
|
| LC50DM: |
7.033 48 hour Daphnia magna LC50. The unit of LC50DM is -log10[(mg/L)/(1000*MW)].
|
LC50FM: |
5.965 96 hour fathead minnow LC50. The unit of LC50FM is -log10[(mg/L)/(1000*MW)].
|
 Species Source
Species Source
| Organism ID | Organism Name | Taxonomy Level | Family | SuperKingdom | Isolation Part | Collection Location | Collection Time | Reference |
|---|---|---|---|---|---|---|---|---|
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | n.a. | n.a. | n.a. |
PMID[10924192] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | n.a. | n.a. | n.a. |
PMID[11754613] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | n.a. | root | n.a. |
PMID[14750033] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | n.a. | n.a. | n.a. |
PMID[15482936] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | roots | n.a. | n.a. |
PMID[18841903] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | Roots | n.a. | n.a. |
PMID[24359277] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | Aerial Parts | n.a. | n.a. |
PMID[24387347] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | n.a. | n.a. | n.a. |
PMID[31642320] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | n.a. | n.a. | n.a. | Database[COCONUT] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | n.a. | n.a. | n.a. | Database[HerDing] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | n.a. | n.a. | n.a. | Database[TCMID] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | n.a. | n.a. | n.a. | Database[TM-MC] |
| NPO20323 | Saururus chinensis | Species | Saururaceae | Eukaryota | n.a. | n.a. | n.a. | Database[UNPD] |
Note for Reference:
In addition to directly collecting NP source organism data from primary literature (where reference will provided as NCBI PMID or DOI links), NPASS also integrated them from below databases:
☉ UNPD: Universal Natural Products Database [PMID: 23638153].
☉ StreptomeDB: a database of streptomycetes natural products [PMID: 33051671].
☉ TM-MC: a database of medicinal materials and chemical compounds in Northeast Asian traditional medicine [PMID: 26156871].
☉ TCM@Taiwan: a Traditional Chinese Medicine database [PMID: 21253603].
☉ TCMID: a Traditional Chinese Medicine database [PMID: 29106634].
☉ TCMSP: The traditional Chinese medicine systems pharmacology database and analysis platform [PMID: 24735618].
☉ HerDing: a herb recommendation system to treat diseases using genes and chemicals [PMID: 26980517].
☉ MetaboLights: a metabolomics database [PMID: 27010336].
☉ FooDB: a database of constituents, chemistry and biology of food species [www.foodb.ca].
 NP Quantity Composition/Concentration
NP Quantity Composition/Concentration
| Organism ID | Organism Name | Organism Material Preparation | Organism Part | NP Quantity (Standard) | NP Quantity (Minimum) | NP Quantity (Maximum) | Quantity Unit | Reference |
|---|
Note for Reference:
In addition to directly collecting NP quantitative data from primary literature (where reference will provided as NCBI PMID or DOI links), NPASS also integrated NP quantitative records for specific NP domains (e.g., NPS from foods or herbs) from domain-specific databases. These databases include:
☉ DUKE: Dr. Duke's Phytochemical and Ethnobotanical Databases.
☉ PHENOL EXPLORER: is the first comprehensive database on polyphenol content in foods [PMID: 24103452], its homepage can be accessed at here.
☉ FooDB: a database of constituents, chemistry and biology of food species [www.foodb.ca].
 Biological Activity
Biological Activity
Molecular-level activity
| Target ID | Target Type | Target Name | Target Organism | Activity Type | Activity Relation | Value | Unit | Reference |
|---|
In vitro activity
| Target ID | Target Type | Target Name | Target Organism | Activity Type | Activity Relation | Value | Unit | Reference |
|---|---|---|---|---|---|---|---|---|
| NPT113 | Cell line | RAW264.7 | Mus musculus | IC50 | = | 14000.0 | nM | PMID[31642320] |
In vivo activity
| Target ID | Target Type | Target Name | Target Organism | Activity Type | Activity Relation | Value | Unit | Reference |
|---|
 Experimental ADME
Experimental ADME
| Experiment Model | Experiment Tissue | ADME Type | ADME Relation | ADME Value | ADME Unit | Reference |
|---|
 Experimental Toxicity
Experimental Toxicity
Quantitative toxicity
| Experiment Model | Experiment Organism | Toxicity Type | Toxicity Relation | Toxicity Value | Toxicity Unit | Reference |
|---|
Common Abbreviations:
LC: Lethal Concentration; LD: Lethal Dose; LT:Lethal Time; NOAEL: No-observed-adverse-effect Level; BMDL: Benchmark Dose Lower Confidence Limit; BMD: Benchmark Dose; BMC:Benchmark Concentration; LOAEL: Lowest Observed Adverse Effect Level; RfD:Reference Dose; RfC:Reference Concentration; MRL: Minimal Risk Level; MEG: Maximum Exposure Guideline; PAC: Protective Action Criteria
Categorical toxicity labels
| Hepatotoxicity | Carcinogenicity | Mutagenicity | Cardiotoxicity | Respiratory Toxicity | Eye Irritation | Endocrine Disruption |
|---|---|---|---|---|---|---|

|

|

|

|

|

|

|
Note for Reference:
In addition to directly collecting NP quantitative data from primary literature (where reference will provided as NCBI PMID or DOI links), NPASS also integrated NP toxicity records from domain-specific databases. These databases include:
☉ ToxValDB: a curated database that compiles quantitative toxicity values for chemicals from diverse public sources to support toxicological research and risk assessment.
☉ TOXRIC: a comprehensive, free-to-access, online database providing toxicological/feature data. The toxicity labels are retrieved from this database. [PMID: 36400569]
 Chemically structural similarity
Chemically structural similarity
Similar Active Natural Products in NPASS
Top-200 similar NPs were calculated against the active-NP-set (includes approximately 50,000 NPs with experimentally-derived bioactivity available in NPASS)
Similarity is measured using the Tanimoto coefficient (Tc) , which compares the binary fingerprints of two molecules. Tc is calculated as the intersection divided by the union of '1' bits in the fingerprints, ranging from 0 to 1, with 1 indicating highest similarity.
● The left chart: Distribution of similarity level between NPC89521 and all remaining natural products in the NPASS database.
● The right table: Most similar natural products (Tc>=0.5 or Top200).
| Similarity Score | Similarity Level | Natural Product ID |
|---|---|---|
| 0.7907 | Intermediate Similarity | NPC294972 |
| 0.6591 | Remote Similarity | NPC28326 |
| 0.6531 | Remote Similarity | NPC485479 |
| 0.6389 | Remote Similarity | NPC203924 |
| 0.5778 | Remote Similarity | NPC601172 |
| 0.5532 | Remote Similarity | NPC218856 |
| 0.5532 | Remote Similarity | NPC210623 |
| 0.5532 | Remote Similarity | NPC226788 |
| 0.551 | Remote Similarity | NPC79184 |
| 0.5306 | Remote Similarity | NPC474119 |
Similar Clinical/Approved Drugs
Similarity level is defined by Tanimoto coefficient (Tc) between two molecules.
● The left chart: Distribution of similarity level between NPC89521 and all drugs/candidates.
● The right table: Most similar clinical/approved drugs (Tc>=0.5 or Top200).
| Similarity Score | Similarity Level | Drug ID | Developmental Stage |
|---|---|---|---|
| NPD |
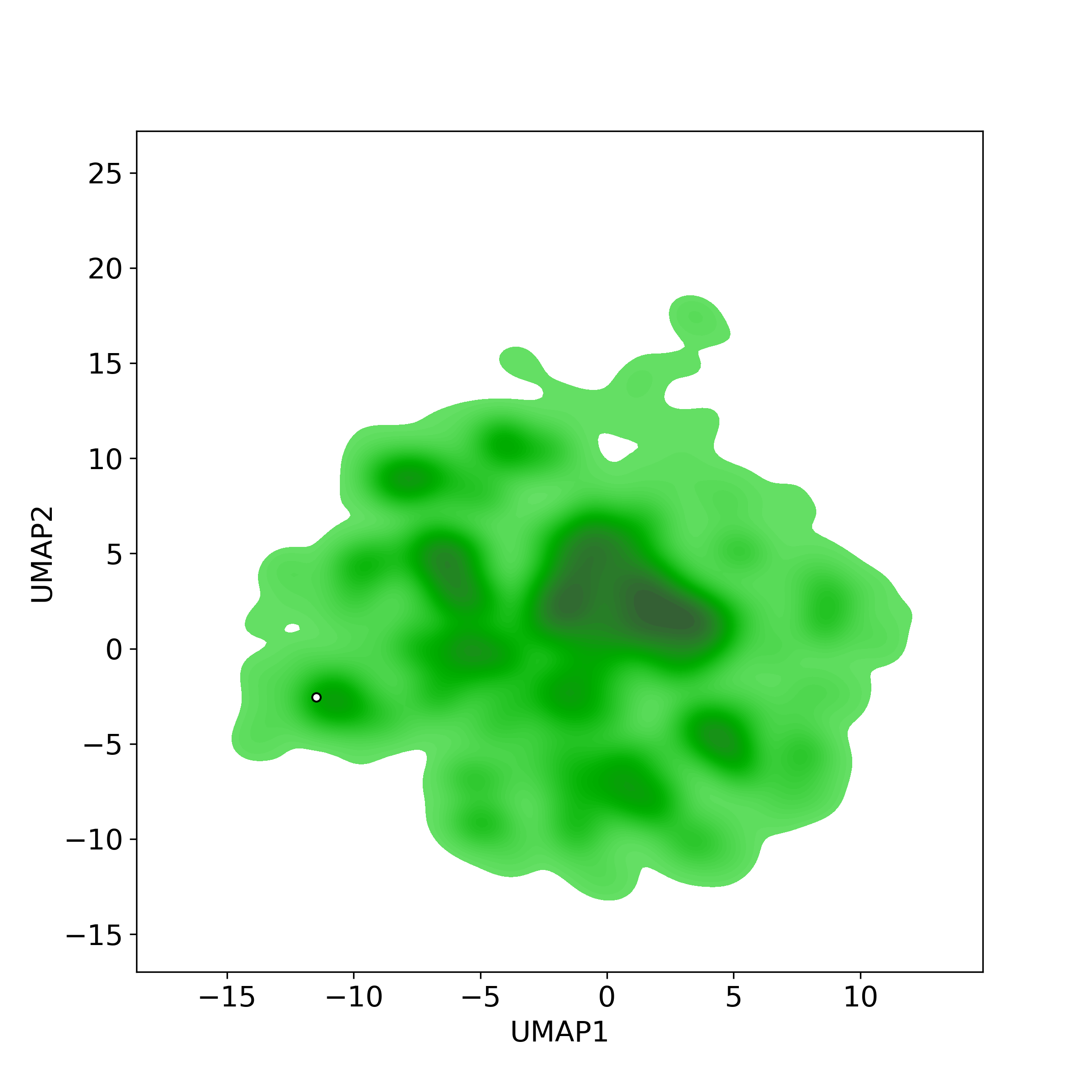
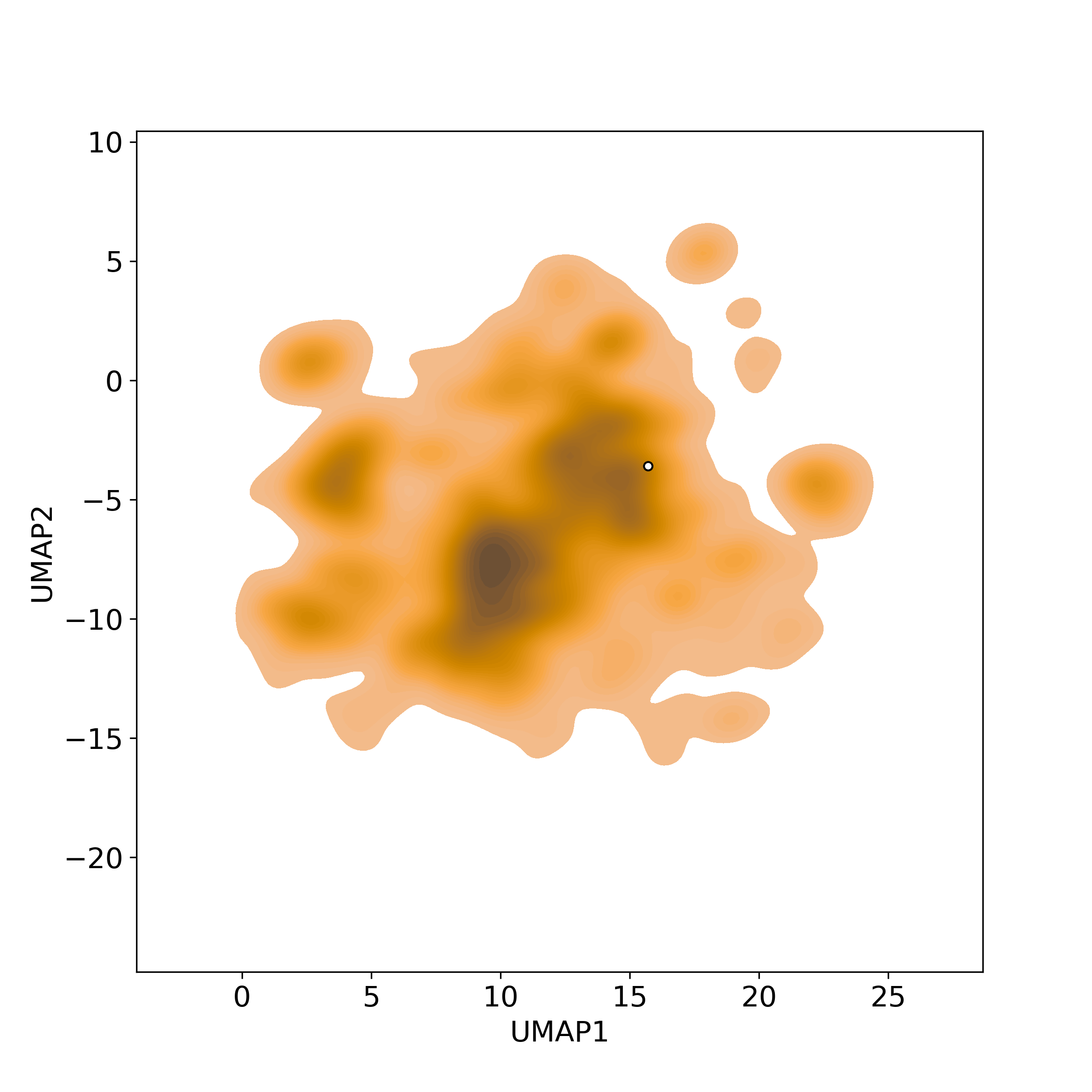
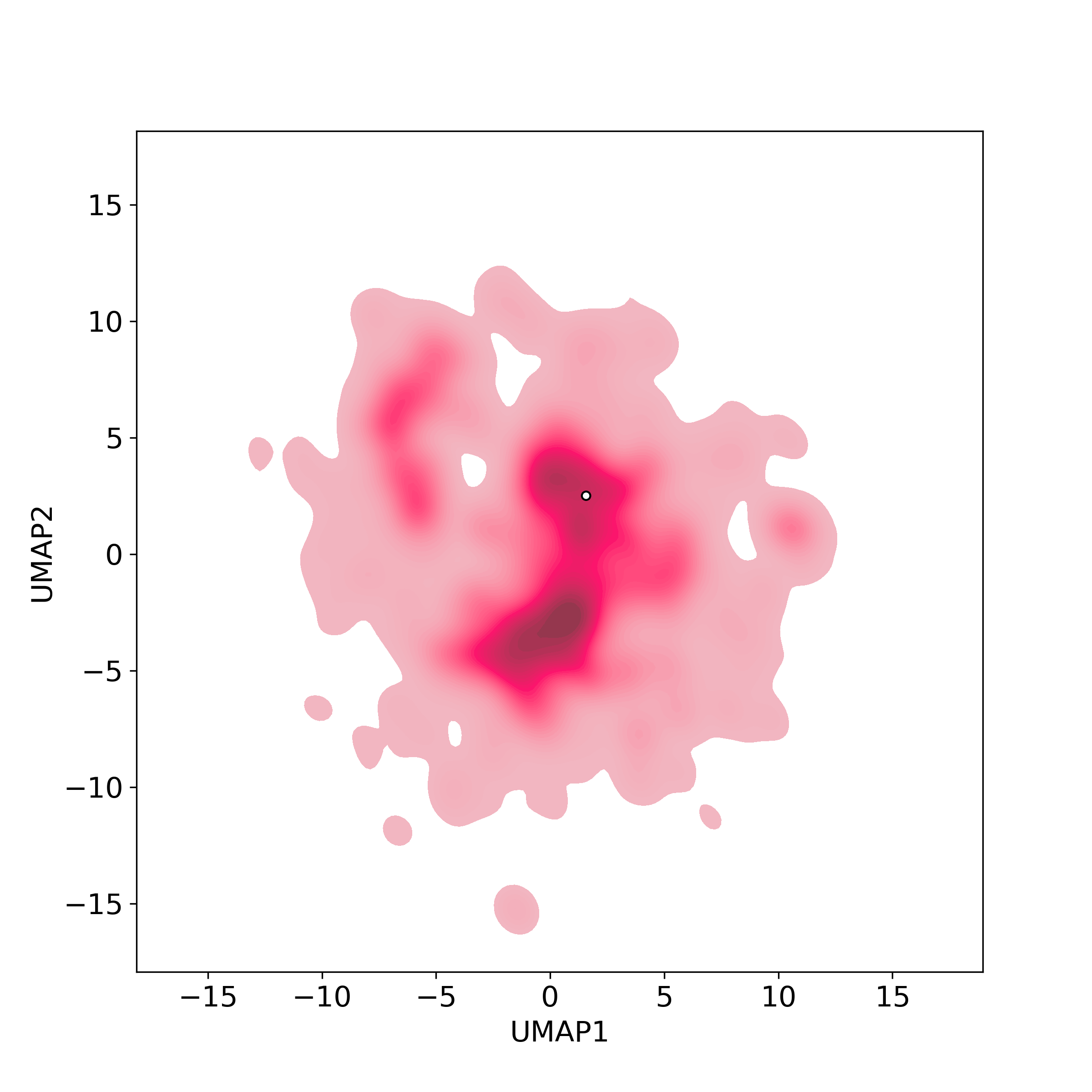
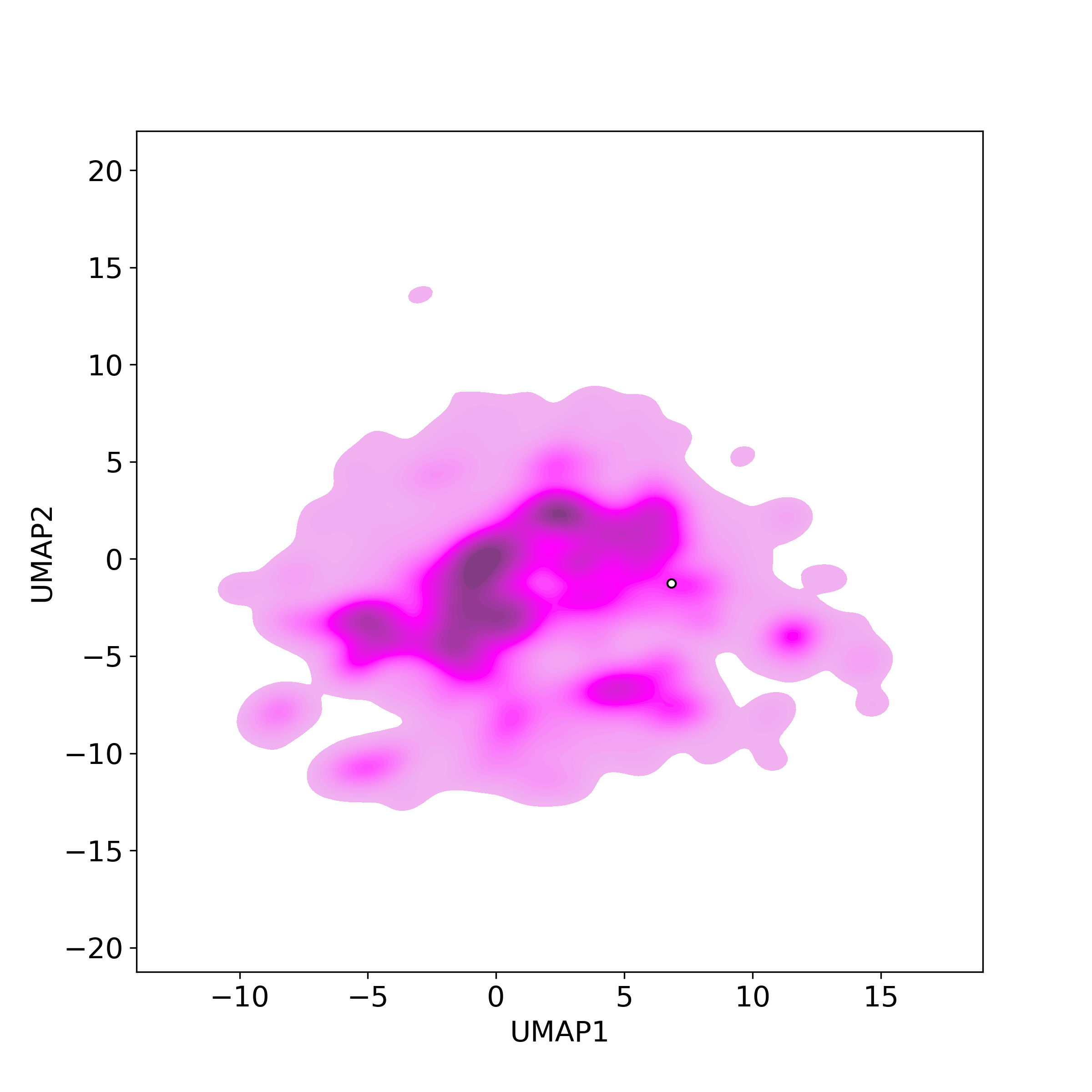
Bioactivity similarity
 Bioactivity similarity
Bioactivity similarity
Similar Natural Products in NPASS
Similarity level is defined by Bioactivity similarity was calculated based on bioactivity descriptors of compounds. The bioactivity descriptors were calculated by a recently developed AI algorithm Chemical Checker (CC) [Nature Biotechnology, 38:1087–1096, 2020; Nature Communications, 12:3932, 2021], which evaluated bioactivity similarities at five levels:
☉ A: chemistry similarity;
☉ B: biological targets similarity;
☉ C: networks similarity;
☉ D: cell-based bioactivity similarity;
☉ E: similarity based on clinical data.
Those 5 categories of CC bioactivity descriptors were calculated and then subjected to manifold projection using UMAP algorithm, to project all NPs on a 2-Dimensional space. The current NP was highlighted with a small circle in the 2-D map. Below figures: left-to-right, A-to-E.